A build is normally a fairly sequential process, and in a big project, a full execution can easily take hours. While one could create such a job on Jenkins, the long turn-around time to the result tends to reduce the value of continuous integration. This page discusses a technique to cope with this problem.
The idea to is to split a big build into multiple stages. Each stage is executed sequentially for a particular build run, but this works like a CPU pipeline and increase the throughput of CI, and also reduces the turn-around time by reducing the time a build sits in the build queue.
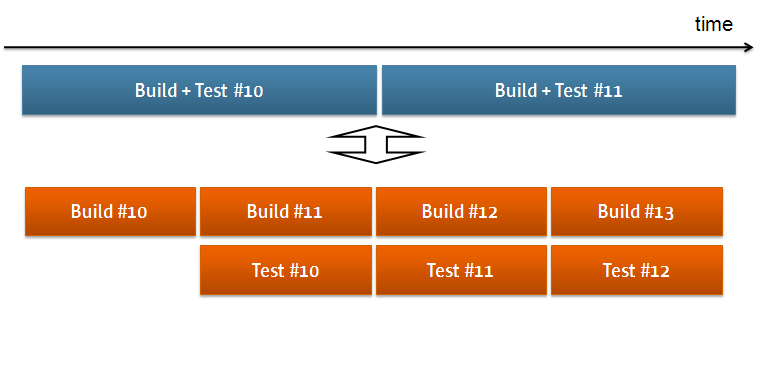
In this situation, your earlier stage needs to pass files to later stages. A general way to do this is as follows:
- An earlier stage archives all the files into a zip/tgz file at the end of the build.
- Tell Jenkins to archive this zip/tgz file as a post-build action, take a fingerprint of it, then trigger the next stage.
- The first thing the next stage does in its build is to obtain this bundle through the permalink for the last successful artifact, then unzip it. Do keep this archive file around because we'll take a fingerprint of it here, too.
- The build proceeds by using the files obtained from the earlier stage.
- Tell Jenkins to fingerprint the zip/tgz file. This allows you to correlate executions of these stages to track the flow.
If you have more than 2 stages, you can repeat this process. In some cases, this "zip/tgz" file would have to contain the entire workspace. If so, the next stage can use the URL SCM plugin to simplify the retrieval.
JENKINS-682 keeps track of an RFE to more explicitly and better support this use case. Please feel free to add yourself to CC, vote, and comment on the issue.
Note: there is a new plugin which helps with this problem: http://wiki.jenkins-ci.org/display/JENKINS/Clone+Workspace+SCM+Plugin